最近工作是帮助券商客户技术平台jres落地
测试反馈架构压测的性能指标不符合预期,只有不到900tps。
jres技术框架在恒生内部的压测中能达到近8w的tps,抛开机器固有性能差异,也不至于下降这么离谱,遂开始排查原因。
目前架构网络拓扑图
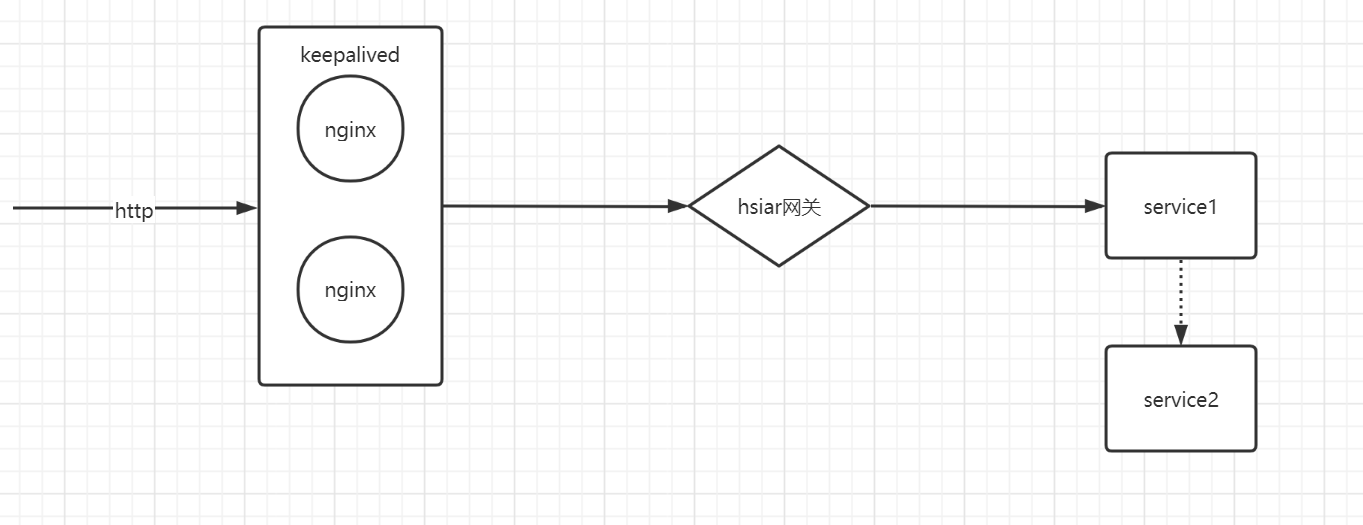
应用服务是我写的一个demo,里面只有一些打印语句还有各服务间远程调用接口。瓶颈不应该会出现在这里。
登录后台服务器磁盘空间、io、cpu的指标
iotop、top、free命令三连击,恒生也提供了see运维管控平台可以可视化观察。
cpu指标20左右浮动,远远没进入瓶颈,所以首先排除机器的原因。
再多次压测的过程中,发现随着并发量的提升,请求总量提升,压测的结果报告中开始出现504报错,引起了我的注意。
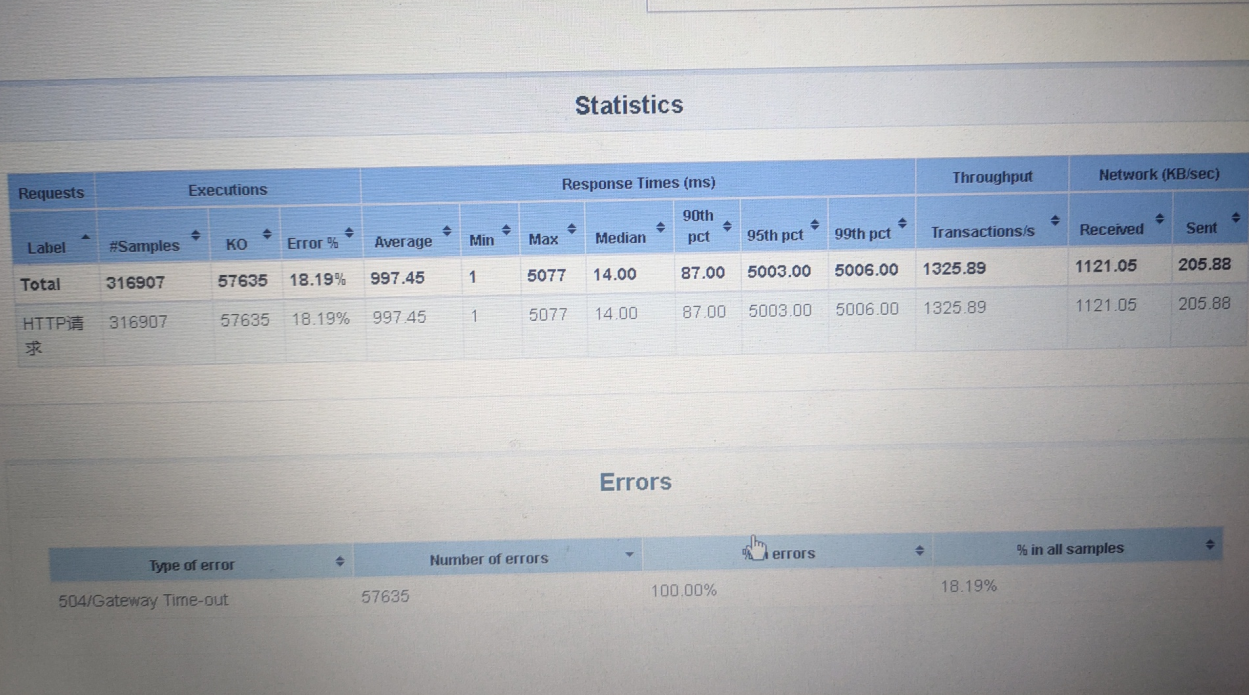
然后跟进log日志搜索504的报错日志,发现在业务日志中没有相关记录,在网关中有记录,目前阶段还是符合我前期的猜测和demo无关。重点排查nginx
开始查阅了资料了解了下nginx的time wait原因,关注到keepalive参数,查看本机的conf配置 keepalive 100;
把keepalive设置为1000,tps开始提升到2w,大喜。后面就是慢慢优化最适合的数值了。
写文的排查步骤很顺利,但是在实际中,走了很多弯路,比如不熟悉jmeter压测工具,设置了吞吐量限制,导致tps一直在1300左右上不去,后面还是同事指出了问题。
总结一下:
综上,出现大量time wait的情况
1)导致 nginx端出现大量time wait的情况有两种:
- keepalive_requests设置比较小,高并发下超过此值后nginx会强制关闭和客户端保持的keepalive长连接;(主动关闭连接后导致nginx出现TIME_WAIT)
- keepalive设置的比较小(空闲数太小),导致高并发下nginx会频繁出现连接数震荡(超过该值会关闭连接),不停的关闭、开启和后端server保持的keepalive长连接;
2)导致后端server端出现大量time wait的情况:
nginx没有打开和后端的长连接,即:没有设置proxy_http_version 1.1;和proxy_set_header Connection “”;从而导致后端server每次关闭连接,高并发下就会出现server端出现大量TIME_WAIT
- 本文标题: 记一次压测的性能提升
- 文章作者: sherryriver(木木三可)
- 发布时间: 2021.05.30
- 本文链接: https://sherryriver.github.io/2021/05/30/记一次压测的性能提升/
- 许可协议: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。